
Читает ли мозг китайский или испанский язык так же, как английский?
На сегодняшний день в мире насчитывается не менее 6 000 языков [ 1 ]. Языки мира представлены различными системами письма, называемыми "орфографиями". Орфографии - это символы, используемые для представления разговорного языка. Сейчас, читая эту статью, вы видите один из видов орфографии! Итак, орфография состоит из символов, используемых для перевода разговорного языка в письменную форму. Однако орфографии различаются по размеру звуковой единицы, которая представлена каждым символом. Например, в алфавитных орфографиях, таких как английская, испанская и русская, каждый символ представляет собой отдельный звук, называемый фонемой (например, звук/b/s в слове "книга" - это одна фонема). В неалфавитных орфографиях, таких как китайская или чероки, символ представляет собой более крупную звуковую единицу, например, слог (например, "pro" в слове "project"). На сегодняшний день существует более 400 орфографий. Каждая орфография может быть классифицирована как алфавитная, например, английская, или неалфавитная, например, китайская. В этой статье мы сначала узнаем о характеристиках различных орфографий. Затем мы используем эти характеристики, чтобы понять, как различные системы письма влияют на процесс чтения. Затем мы узнаем об областях мозга, участвующих в процессе чтения.
Сначала поговорим об алфавитных орфографиях. Существует несколько различных алфавитов, которые используются для создания письменных языков. Например, в английском языке используется латинский алфавит и 26 символов, или букв, для представления разговорного языка. Норвежский и словацкий языки также используют латинский алфавит или тот же набор символов, но норвежский включает три гласных, не используемых в английском (å, æ, ø), а словацкий использует ряд знаков ударения, чтобы указать, как произносится буква (например, ó или š), в результате чего для представления разговорного языка используется 46 символов. Большинство европейских языков, включая английский, французский, испанский, итальянский, голландский, норвежский, немецкий, португальский, чешский, словацкий, венгерский, польский, датский, валлийский, шведский, исландский, финский и турецкий, используют латинский алфавит [1].
Существуют и другие алфавиты, которые используют различные наборы символов для представления разговорного языка, но при этом кодируют язык на уровне фонем. К таким алфавитам относятся кириллица, которая используется в русском, болгарском и украинском языках; алфавит деванагари, который используется для хинди, одного из официальных языков Индии; греческий алфавит, который используется только для греческого языка; и алфавит хангыль, который используется для корейского языка. Некоторые языки, например сербохорватский, используют и латинский, и кириллический алфавиты. Алфавитная орфография, содержащая только согласные, но не гласные, называется "абджад". Иврит и арабский иногда относят к абжадам, поскольку гласные традиционно не включаются в письмо. Однако сегодня мы часто используем знаки ударения, чтобы показать, где должна находиться гласная, поэтому многие люди относят иврит и арабский к алфавитам, а не к абжадам. На рисунке 1 вы можете сравнить несколько различных алфавитных (и неалфавитных) орфографий, используемых для записи одного и того же утверждения: "Я думаю, я могу".
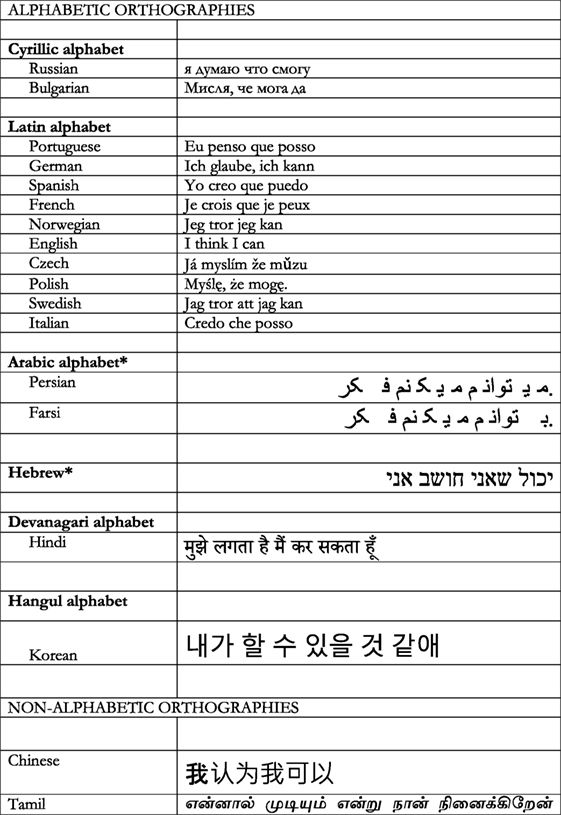
Алфавитные орфографии также различаются тем, насколько хорошо сочетаются фонемы (звуки) и графемы (символы или буквы). В некоторых языках, таких как испанский, итальянский и немецкий, почти каждая буква обозначает только один звук. Когда каждая буква всегда произносится одинаково, говорят, что это совпадение, а орфографию называют "поверхностной". В других языках, таких как английский и датский, у буквы может быть много вариантов произношения, например, два разных звука/c/s в слове "circus". В этом случае говорят о "непоследовательном" произношении, а орфографию называют "глубокой". Таким образом, испанский язык - это последовательная, или неглубокая, орфография, а английский - непоследовательная, или глубокая, орфография. Хотя не все согласны с тем, как сравнивать соответствия между буквами и звуками в разных языках, исследователи в целом согласны с тем, что финский, греческий, итальянский, испанский, немецкий, сербохорватский, турецкий и корейский языки имеют относительно поверхностную или последовательную орфографию, тогда как португальский, французский и датский содержат больше непоследовательных соответствий между фонемами и графемами. Английский - самый непоследовательный язык в мире!
Теперь поговорим о неалфавитных орфографиях. В неалфавитных орфографиях каждому символу соответствует либо слог (например, чероки, тамильский язык или японская кана), либо односложная смысловая единица (как в китайском языке, японских кандзи). Как и в алфавитных орфографиях, единица разговорного языка представлена символом, но в неалфавитных орфографиях, в отличие от алфавитных, эта единица разговорного языка больше, чем просто фонема. Китайский язык часто называют пиктографией (язык, состоящий из картинок), потому что люди думают, что иероглифы - это изображения слов, которые они обозначают. На самом деле, очень немногие китайские иероглифы являются изображениями слов, которые они обозначают. Скорее, в китайском языке символы представляют собой единицу произношения (слог), которая также является единицей значения (морфема), поэтому китайский язык считается морфо-слоговой системой письма. Примерно 80-90 % китайских иероглифов также содержат так называемый фонетический радикал. Фонетический радикал - это одна из частей иероглифа, которая дает подсказку, как произнести слово. Примеры китайского и тамильского языков показаны на рисунке 1.
Как мы видим, есть некоторые вещи, которые одинаковы для всех орфографий, и есть некоторые вещи, которые различаются между орфографиями. Все орфографии представляют разговорный язык с помощью письменных символов. Тем не менее, часть разговорного языка, которая кодируется, и последовательность сопоставления звуков и символов в разных орфографиях различны. Далее мы изучим, как эти сходства и различия влияют на навыки чтения, и посмотрим, как мозг читает на разных языках.
Труднее ли научиться читать в одних орфографиях, чем в других?
Скорость и качество обучения детей чтению в разных языках различны. Некоторые из этих различий обусловлены особенностями системы письма [ 2 ]. В одном большом исследовании сравнивались дети, обучающиеся чтению по 14 различным алфавитным орфографиям, и было обнаружено, что к концу первого класса дети, обучающиеся чтению по неглубоким орфографиям, таким как испанская, финская и греческая, допускали меньше ошибок при чтении и читали быстрее, чем дети, обучающиеся чтению по более непоследовательным орфографиям, таким как датская и английская [2]. Некоторые различия в обучении чтению на разных языках могут объясняться тем, что в разных странах детей учат читать по-разному. Однако исследования в подавляющем большинстве случаев подтверждают идею о том, что научиться читать легче в последовательных орфографиях, чем в непоследовательных. Для обучения чтению на английском языке требуется больше времени, чем для обучения чтению на почти всех других алфавитных орфографиях, а для обучения чтению на китайском языке - еще больше [ 3 ].
Есть ли у детей разные проблемы с чтением в разных орфографиях?
У детей, которые с большим трудом учатся читать, может быть проблема с обучением, известная как дислексия. Дети с дислексией не умеют читать так же хорошо, как другие дети того же возраста. Кроме того, их трудности с чтением не связаны с плохим преподаванием, плохим зрением или слухом или с другими нарушениями работы мозга. Считается, что около 5 % детей на всех языках имеют серьезные проблемы с чтением.
Дети с дислексией, говоря на любом языке, с трудом преобразуют письменные символы в звуки, которые они обозначают [3]. Этот навык называется фонологическим декодированием. Однако степень, в которой проблемы с фонологическим декодированием мешают чтению, различается в разных языках. Дети с дислексией в языках с постоянной орфографией, таких как немецкий, испанский и итальянский, могут правильно читать слова, что свидетельствует о наличии у них хороших навыков фонологического декодирования, но они, как правило, очень медленно читают. Напротив, проблемы с фонологическим декодированием сильно влияют на чтение в непоследовательных орфографиях, таких как английская. Дети с дислексией в английском языке склонны делать много ошибок при чтении слов [3]. Дети с дислексией в китайском языке, неалфавитном языке, также имеют проблемы с фонологическим декодированием, что может повлиять на чтение. Китайские читатели, у которых есть проблемы с фонологическим декодированием, могут не уметь использовать фонетические радикалы в китайском иероглифе как подсказку для произношения этого слова. Однако неспособность использовать фонетические радикалы в китайском иероглифе не является основной проблемой для китайских детей с дислексией. В китайском языке понимание того, как иероглиф представляет значение слова, - навык, называемый "морфологической осведомленностью", - является более важным навыком для чтения, и у детей с дислексией часто возникают проблемы с этим навыком [ 4 ]. Таким образом, фонологическое декодирование важно для обучения чтению на китайском языке, но, вероятно, менее важно, чем для детей с дислексией.
Мы видим сходства и различия в чтении в разных орфографиях. То, насколько быстро и хорошо дети учатся читать, частично зависит от особенностей орфографии. Фонологическое декодирование важно для чтения во всех орфографиях, но в разной степени, в зависимости от системы отображения, которая используется в конкретной орфографии. Что означают эти сходства и различия с точки зрения того, как мозг читает различные орфографии?
Существует ли универсальная сеть мозга для чтения в разных орфографиях?
Несмотря на различия в том, как быстро дети учатся читать, и в том, какие проблемы возникают у детей при чтении на разных орфографиях, есть основания полагать, что при чтении на всех языках задействуются одни и те же участки мозга. Первый шаг при чтении на любом языке - это взгляд на печатное слово и его анализ. Кроме того, все орфографии представляют собой разговорный язык, что предполагает, что фонологическое декодирование, или определение того, какие звуки обозначают символы, требуется для любого чтения. Исследования визуализации мозга, в ходе которых с помощью специального оборудования делаются "снимки" мозга, могут многое рассказать о том, как мозг читает различные орфограммы. Наиболее распространенные методы визуализации мозга, используемые для изучения чтения языков, называются функциональной магнитно-резонансной томографией (фМРТ) и позитронно-эмиссионной томографией (ПЭТ). И фМРТ, и ПЭТ-сканирование создают изображения мозга, когда он работает над задачей, позволяя исследователям увидеть, какие области мозга задействованы во время чтения. Используя эти инструменты для сравнения активности мозга при чтении различных орфограмм, исследователи могут определить области мозга, которые используются при чтении всех орфограмм, и области мозга, которые используются только при чтении определенных орфограмм.
Одна группа исследователей определила три области в левом полушарии (или стороне) мозга, которые используются при чтении во всех изученных орфографиях [ 5 ]. Эти исследователи объединили результаты 43 различных фМРТ и ПЭТ исследований чтения на нескольких различных языках, включая английский, французский, итальянский, немецкий, датский, китайский, японские каны и японские кандзи. Во всех орфографиях использовались три области мозга: область в верхней части левой височной доли в задней части мозга под названием височно-теменная область, которая может быть вовлечена в фонологическое декодирование, область в нижней части левой лобной доли под названием нижняя лобная извилина и область зрительной формы слова (VWFA). VWFA - это область фузиформной извилины, которая расположена вдоль нижней части височной и затылочной долей в левом полушарии коры головного мозга (см. рис. 2). Считается, что VWFA задействуется только при восприятии письменных букв и слов, но не при восприятии других объектов, и было установлено, что VWFA участвует в чтении во всех изученных на данный момент орфографиях [ 6 ].

Эта же группа исследователей выявила несколько областей мозга, которые задействовались только при чтении определенной орфографии. Например, фузиформная извилина в правом полушарии (стороне) мозга была активна при чтении китайского, но не других языков. Такая картина активности мозга означает, что при чтении китайского языка задействуются фузиформные извилины как левого, так и правого полушария, но при чтении любой из алфавитных орфографий используется только фузиформная область левого полушария - VWFA. Исследователи полагают, что области мозга, задействованные только при чтении китайского языка, могут быть использованы для установления связей между значением и звуками слова, а также при чтении квадратной формы китайских иероглифов.
Чтение - сложная задача и относительно новый навык для человека. Вполне вероятно, что некоторые области мозга со временем адаптировались к чтению или стали лучше справляться с этой задачей. Исследования показывают, что существуют некоторые общие области мозга, участвующие в чтении на всех языках, - области, которые участвуют в визуальном распознавании символов и определении звуков, которые эти символы обозначают. Однако существуют и специализированные области мозга, которые поддерживают особые навыки, необходимые для чтения конкретной орфографии. Большинство исследований, проведенных до настоящего времени, были посвящены алфавитным орфографиям, в основном основанным на латинском алфавите. Для того чтобы точно знать, читает ли мозг на всех языках одинаково, необходимы дальнейшие исследования, направленные на изучение чтения в других орфографиях.


